How to Implement a K Nearest Neighbor Algorithm

Today, I would like to talk about K-Nearest Neighbors. Easier known as KNN. This happens to be known as one of the simpler classification algorithms and is happens to be one of the most used in learning algorithms. This method is preffered by many in the industry because of its ease of use and low calculation time.
I know many of you are wondering, well what is KNN? KNN is a model that classifies data points based on the points that are most similar to it. KNN uses test data to make an educated guess on what an unclassified point should be classified as. KNN is often used in simple recommendation systems, image recognition technology, and decision-making models. It is the algorithm companies like Netflix or Amazon use in order to recommend different movies to watch or books to buy.
Planning with a KNN Classifier algorithm goes as this:
1) Get a clean dataset. You don’t want any missing values or mixes
2) You will need to find a point to classify. It has to have the same number of features.
3) You need to find the K closest elements from the dataset to the point in question. The K is usually an odd number so it avoids any ties.
4) Now you want to classify that point based on the classification of its neighbors.
The steps 1&2 will require you to do feature engineering and data cleaning. Feature engineering is the process of using domain knowledge to extract features from raw data via data mining techniques. These features can be used to improve the performance of machine learning algorithms. Data cleaning is the process of detecting and correcting or removing inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data.
Step 3 is when we find the K closest elements to the point and it is the main part of this algorithm. There are multiple ways to calculate the distance in Data Science. For me, the most straightforward way is the Euclidean Distance. The calculation for Euclidean is the square root of the Sum of Squares of the Differences between the two points. I know I definetely won’t remember that in my head but it’s an easy concept. Here is an example of the formula shown below.
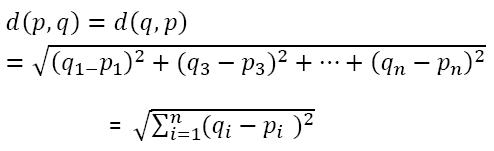
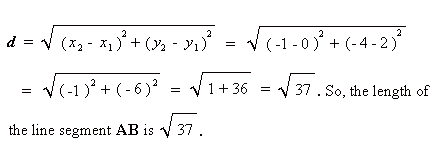
Now that you have an idea, I can begin to show you how we code this distance method in Python.
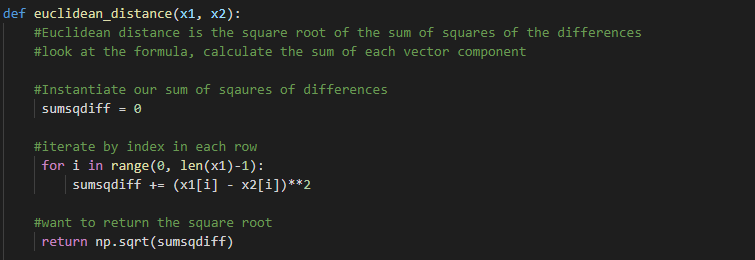
The function takes in two data points that are the same length. We want to iterate through each index of x1, find its value, and subtract the value at the same index position in x2. After squaring the difference, we then add that value to the existing distance total. Finally, we take the square root of the total distance to get the Euclidean distance between two points of data.
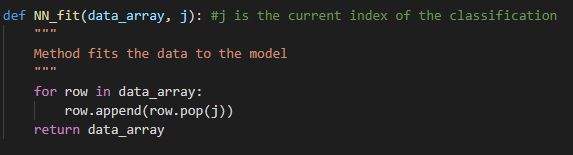
Now that we have a working Euclidean Distance function, we can now move on and iterate through to find the K-Nearest Neighbors to our point. Now, since KNN models require datasets to be stored, our fit method is simply pulling the cleaned data into an array. Then, we will move the classification feature to the last element in each row. When calling the fit() method, it will store the data to be used when we want to make a prediction.
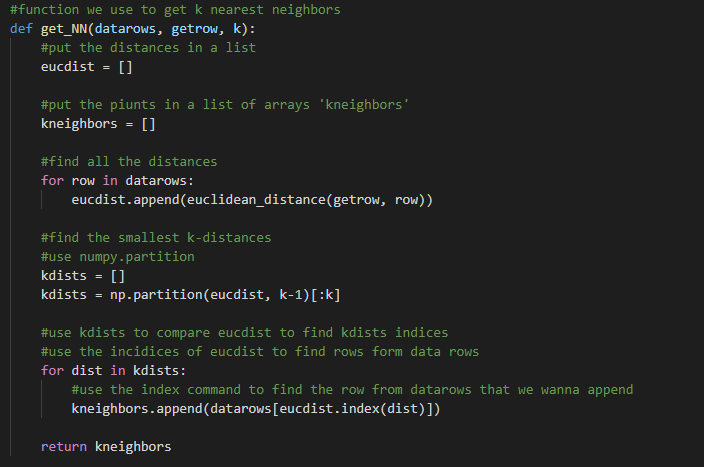
Since we just recently fitted the model, we can find the nearest neighbors. First, we put the distances in a list then, put the points is a list of arrays. I want to find all the distances. After we do that, I can find the smallest distances. I used numpy partition which creates a copy of the array with its elements rearranged in such a way that the value of the element in the k position is in the position it would be in a sorted array. Then I use the index command to find the row from dattarows I would like to append.
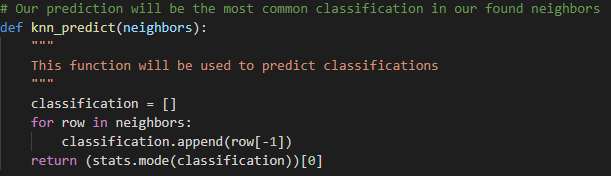
Now that step 3 is completed, we can move on. Next, we are going to be making the prediction based on the classifications. For this model, we will be taking the mode of the K-Nearest Neighbors’ classifications. Here is how I implemented my prediction model:
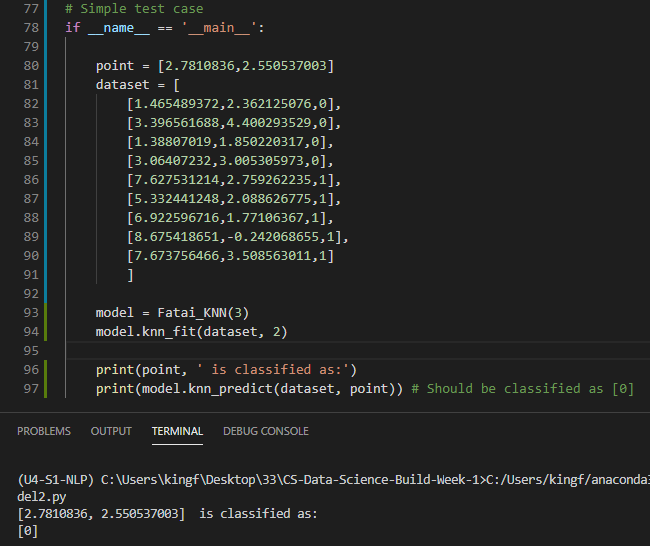
The 3 nearest neighbors all have classifications of ‘0’. So we will predict that our reference point
will also have a classification of ‘0’. Here is the results I got based on my prediction model:
Here is a link to my Github repo. Here you will find my code which looks a lot cleaner than what is shown above.
You must beware of the Curse of Dimensionality when using KNN model. KNN models are appropriate for datsets with only a few features. As the number of features increases, the sparsity of the data will increase exponentially, meaning that the data will become less and less ‘close’. The smaller the dataset, the fewer the features we will use. Next, don’t forget about feature engineering and data cleaning. These steps are very important into having an accurate KNN model. Do your research. It is important to learn the correct practices for using this algorithm so you are finding the most accurate results from your data set. Hopefully with this said, you are now able to implement your own KNN classification. Enjoy!